Dalam arsitektur sistem komputasi modern, kemampuan untuk menyesuaikan sumber daya secara dinamis atau yang dikenal dengan dynamic resource scaling menjadi fondasi penting untuk mencapai efisiensi operasional dan ketangkasan. Konsep ini sangat relevan pada platform berbasis slot, di mana unit alokasi sumber daya dapat disesuaikan secara real-time dengan kebutuhan beban kerja. Artikel ini membahas Kajian implementasi dynamic resource scaling slot.
Memahami Konsep Dasar Dynamic Resource Scaling
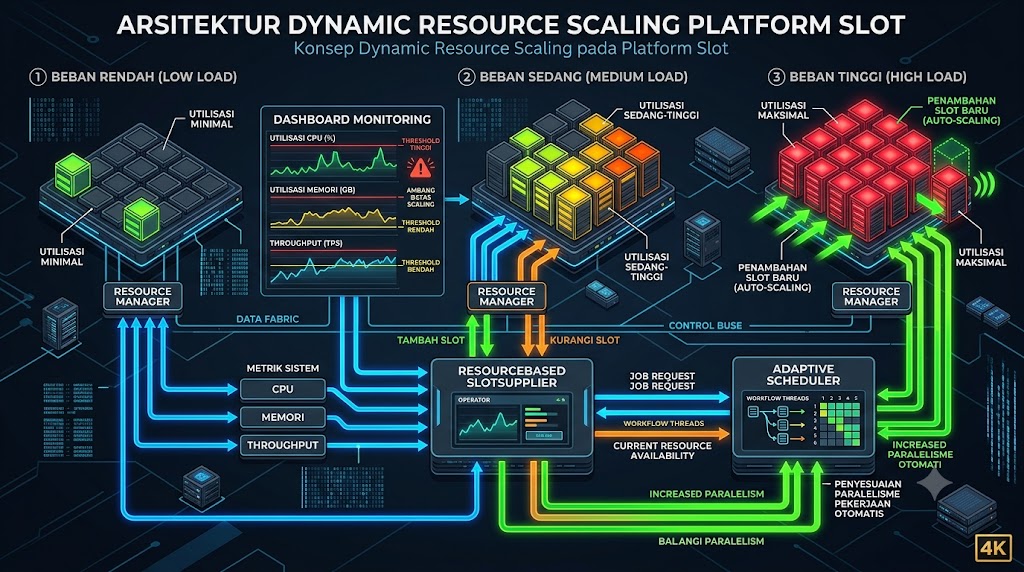
Dynamic resource scaling adalah mekanisme yang memungkinkan sistem menyesuaikan jumlah slot atau kapasitas sumber daya secara otomatis berdasarkan permintaan aktual. Tujuan utamanya adalah menjaga keseimbangan antara performa dan biaya: menyediakan cukup sumber daya untuk memenuhi beban kerja tanpa pemborosan kapasitas yang tidak terpakai. Dalam implementasi seperti Apache Flink, scaling dapat dilakukan dengan menyesuaikan paralelisme pekerjaan secara dinamis, menambah atau mengurangi slot saat dibutuhkan .
Pendekatan ini berbeda secara fundamental dari model statis di mana jumlah slot ditentukan di awal dan tidak berubah selama siklus hidup aplikasi.
Pendekatan Resource-Based Slot Supplier
Salah satu implementasi paling canggih dari dynamic scaling adalah pendekatan resource-based slot supplier. Dalam model ini, jumlah slot yang dikeluarkan disesuaikan secara dinamis berdasarkan penggunaan sumber daya sistem yang sebenarnya, seperti CPU dan memori .
Mekanisme ini bekerja dengan menetapkan target utilisasi CPU dan memori, dan sistem akan secara otomatis menambah atau mengurangi jumlah slot untuk mencapai target tersebut. Pendekatan ini sangat efektif untuk beban kerja yang fluktuatif dan tidak dapat diprediksi dengan mudah . Sebagai contoh, dalam implementasi di Temporal, ResourceBasedSlotSupplier akan mengeluarkan slot baru hanya jika penggunaan CPU atau memori masih di bawah ambang batas yang ditentukan, mencegah oversubscription dan kehabisan sumber daya .
Penting untuk dicatat bahwa dalam lingkungan kontainer, implementasi ini memanfaatkan cgroups untuk memperhitungkan penggunaan CPU dan memori di tingkat kontainer, memberikan visibilitas yang akurat tentang konsumsi sumber daya aktual .
Pendekatan Berbasis Metrik Kinerja
Pendekatan lain yang umum digunakan adalah scaling berdasarkan metrik kinerja seperti throughput, latensi, atau tingkat antrian. Metrik yang digunakan meliputi rata-rata waktu pemrosesan data, jumlah record yang masuk dan keluar, ukuran backlog, dan total jumlah split yang dapat diproses secara paralel .
Pendekatan ini memungkinkan sistem untuk secara proaktif menyesuaikan kapasitas berdasarkan indikator performa aktual, bukan hanya berdasarkan utilisasi sumber daya mentah. Misalnya, jika backlog terus meningkat meskipun utilisasi CPU masih rendah, sistem dapat menambahkan slot untuk mempercepat pemrosesan .
Adaptif Scheduler pada Apache Flink
Scheduler ini akan mengurangi paralelisme jika tidak ada cukup slot untuk menjalankan pekerjaan dengan konfigurasi awal, dan akan meningkatkan paralelisme kembali ketika slot baru tersedia .
Keunggulan utama Adaptive Scheduler adalah kemampuannya menangani kegagalan TaskManager dengan anggun. Ketika sebuah TaskManager hilang, sistem akan secara otomatis menurunkan skala untuk menyesuaikan dengan kapasitas yang tersisa, dan akan meningkatkan skala kembali ketika sumber daya pulih . Ini sangat penting untuk lingkungan cloud-native di mana kegagalan komponen adalah hal yang wajar.
Reactive Mode dan Ekosistem Autoscaling
Reactive Mode adalah mode khusus dari Adaptive Scheduler yang mengasumsikan satu pekerjaan per cluster dan mengonfigurasi pekerjaan untuk selalu menggunakan semua sumber daya yang tersedia . Dalam mode ini, menambahkan TaskManager akan meningkatkan skala pekerjaan, sementara menghapus sumber daya akan menurunkannya.
Reactive Mode memungkinkan implementasi autoscaling yang kuat dengan mengandalkan layanan eksternal untuk memantau metrik seperti consumer lag, utilisasi CPU agregat, throughput, atau latensi. Ketika metrik ini melewati ambang batas tertentu, TaskManager tambahan dapat ditambahkan atau dihapus dari cluster Flink . Layanan eksternal ini dapat diimplementasikan melalui perubahan faktor replika pada deployment Kubernetes atau menggunakan autoscaling group di cloud provider.
Pendekatan ini memisahkan tanggung jawab: layanan eksternal menangani alokasi dan dealokasi sumber daya, sementara Flink mengelola penjadwalan dan eksekusi pekerjaan dengan sumber daya yang tersedia .
Dinamika Alokasi Slot pada BigQuery
Google BigQuery menawarkan contoh implementasi autoscaling slot yang lebih terstruktur melalui reservasi. Reservasi dapat dikonfigurasi dengan slot baseline (jumlah minimum slot yang selalu dialokasikan) dan slot autoscaling (slot tambahan yang ditambahkan sesuai kebutuhan) .
Mekanisme scaling di BigQuery bekerja dengan prioritas yang jelas: baseline slots digunakan terlebih dahulu, kemudian idle slot sharing dari reservasi lain, dan terakhir autoscale slots . Scaling dilakukan hampir secara instan, dengan kenaikan kelipatan 50 slot berdasarkan penggunaan aktual .
Yang menarik, BigQuery menerapkan scale-down window minimal 60 detik, di mana slot yang telah ditingkatkan skalanya dipertahankan setidaknya selama periode tersebut . Setiap puncak kapasitas akan mereset window ini, mencegah fluktuasi scaling yang terlalu sering dan memberikan stabilitas pada beban kerja .
Praktik Terbaik Implementasi
Tentukan Baseline dan Maksimum yang Realistis
Tetapkan jumlah slot minimum (baseline) berdasarkan beban kerja normal, dan maksimum berdasarkan proyeksi beban puncak. Baseline memastikan kapasitas selalu tersedia, sementara maksimum mencegah biaya yang tidak terkendali .
Pantau dan Sesuaikan Secara Berkala
Autoscaling bukanlah pengaturan “set-and-forget”. Pantau secara aktif tingkat kegagalan, performa, dan biaya, lalu sesuaikan parameter scaling sesuai kebutuhan .
Perhatikan Periode Stabilisasi
Implementasi seperti HPA di Kubernetes memiliki stabilization window yang mencegah fluktuasi scaling yang terlalu sering. Untuk scaling up, defaultnya adalah 60 detik; untuk scaling down, 300 detik . Pastikan parameter ini disesuaikan dengan karakteristik beban kerja Anda.
Hindari Konflik dengan Vertical Scaling
Horizontal Pod Autoscaler dan Vertical Pod Autoscaler tidak boleh digunakan bersamaan dengan metrik yang sama, karena dapat menyebabkan konflik keputusan scaling .
Kesimpulan
Kajian implementasi dynamic resource scaling pada slot menunjukkan bahwa pendekatan yang tepat bergantung pada karakteristik beban kerja dan arsitektur sistem. Resource-based scaling menawarkan adaptivitas terhadap fluktuasi sumber daya, sementara metric-based scaling memberikan respons terhadap indikator performa aktual. Framework seperti Adaptive Scheduler Flink dan BigQuery autoscaling menyediakan mekanisme yang matang untuk mengimplementasikan scaling secara efektif.
Kunci keberhasilan terletak pada pemahaman tentang trade-off: scaling up yang terlalu agresif dapat meningkatkan biaya, sementara scaling down yang terlalu cepat dapat menyebabkan degradasi performa. Dengan menerapkan praktik terbaik seperti penetapan baseline dan maksimum yang realistis, pemantauan berkala, dan konfigurasi stabilization window yang tepat, platform berbasis slot dapat mencapai keseimbangan optimal antara efisiensi sumber daya dan performa layanan.